

An incident response plan documents an organization’s approach to responding to incidents. The plan should meet your requirements related to your mission, size, and structure.
The purpose of this blog is to:
This blog builds on our previous blog on writing an incident response policy. This blog will not discuss mission, purpose, strategies, goals or management approval sections. These sections do appear in our plan but we covered them in our previous blog.
Components of an incident response plan
This blog will focus on the creation of an incident response plan. We found two authoritative sources detailing components of an incident response plan. The first source is NIST SP 800-61 Rev 2 which is the Computer Security Incident Handling Guide. The second is from Carnegie Mellon University (CMU). Their publication is Incident Management Capability Assessment.
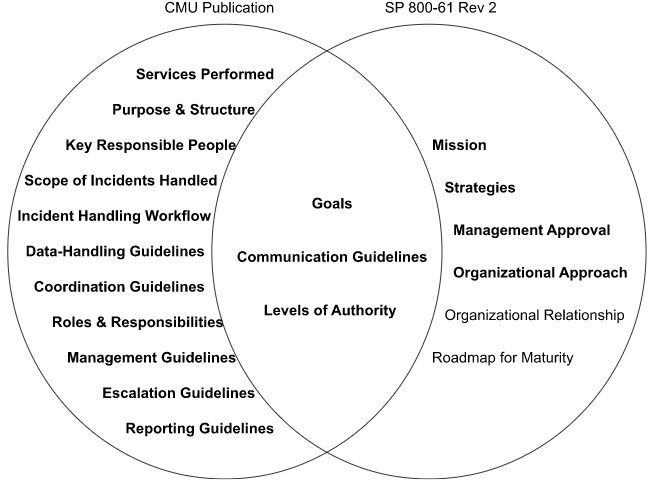
The plan elements cited by CMU go well beyond the requirements listed by NIST. Each organization will tailor their own elements into their plan.
For our template, we opted to incorporate those headings with bold font in the venn diagram. We tailored out the organizational relationship as it is specific to each organization. Organizations can use the template as a benchmark for their own maturity.
Incident Management Philosophy
Defining the organization’s philosophy to incident management helps define the services performed. Incident management is a broader term that describes activities outside of incident handling. Incident response is the last step in the incident handling process.

Incident Management Process Overview
The five steps defined in our incident management model include:
Prepare - planning, implementing and sustaining an incident management capability
Protect - stop or mitigate incidents and vulnerabilities
Detect - notice events through proactive monitoring and receive reports of events
Triage - categorize, prioritize and assign events for handling or response
Respond - analyze the event and coordinate a response strategy
Preparing and protecting support the incident response capability. These processes involve putting staff, technologies, policies and procedures in place . The Detect, Triage, and Respond processes are sequential. Responses can inform future preparation and protection processes.

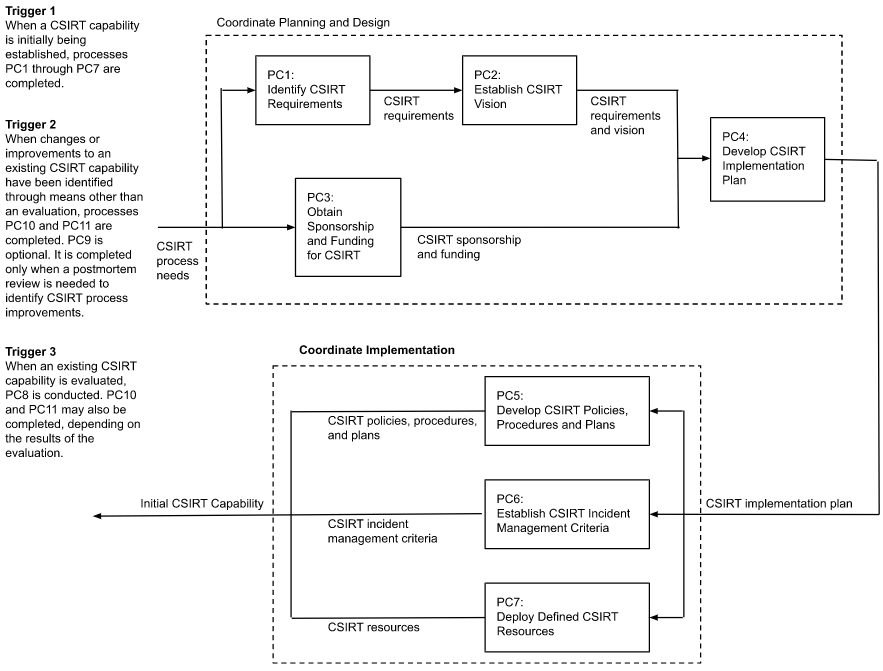
Prepare, Sustain and Improve CSIRT Process Overview

Protect Infrastructure Workflow Overview

Detect Events, Triage Events, and Respond Workflow Overview

Services Performed
Identifying the processes allows us to define the specific services performed.
Establish the Incident Management and Control Process
Plan for Incident Management
Assign Staff to Incident Management Plan
Detect Events
Detect and Report Events
Log and Track Events
Collect, Document, and Preserve Event Evidence
Analyze and Triage Events
Declare and Analyze Incidents
Declare Incidents
Analyze Incidents
Respond to and Recover from Incidents
Escalate Incidents
Develop Incident Response
Communicate Incidents
Close Incidents
Establish Incident Learning
Perform Post-Incident Review
Translate Experience into Strategy
Scope of Incidents Handled
We categorize incidents using the CSIRT Case Classifications. The Forum of Incident Response and Security Teams (FIRST) manages this publication. We created categories in our plan to identify who handles these categories. We identify any external organizations who handle incidents on our behalf.

Prepare
Preparation includes establishing a capability to respond and preventing incidents.
Incident Handler Communication and Facilities
Contact Information for team members include phone numbers, and email addresses
On-call Information for other teams within the organization
Incident reporting mechanisms that users can use to report suspected incidents
Issue tracking system for tracking incident information
Smartphones for off-hour support communications
Encryption software for internal and external communications
War room for central communication and coordination
Secure storage facility for securing evidence and other sensitive materials
Incident Analysis Hardware and Software
Digital forensic workstations and/or backup devices to save relevant incident data
Laptops for activities such as analyzing data, sniffing packets, and writing reports
Spare workstations, servers, and networking equipment for many purposes
Blank removable media
Portable printer to print copies of evidence from non-networked systems
Packet sniffers and protocol analyzers to capture and analyze network traffic
Digital forensic software to analyze disk images
Removable media with trusted versions of programs for gathering evidence
Evidence gathering accessories to preserve evidence for possible legal actions
Incident Analysis Resources
Port lists, including commonly used ports and Trojan horse ports
Documentation for OSs, applications, protocols, intrusion detection and antivirus
Network diagrams and lists of critical assets, such as database servers
Current baselines of expected network, system, and application activity
Cryptographic hashes of critical files to speed incident analysis, verification, and eradication
Incident Mitigation Software
Access to images of clean OS and applications for restoration and recovery purposes
We outfitted each incident response team with a jump kit. The jump kit contains many of the same materials listed above and is ready to go at all times. The laptop performs packet sniffing, malware analysis, and other actions that risk contamination. We reinstall all software software applications before using it for another incident.
Prepare Workflow Diagram

Protect
The incident response team plays a critical role identifying security gaps. Securing networks, systems and applications is outside the scope of incident management. Keeping the number of incidents low protects the incident response process. We opted to include a brief summary of some of the main practices for securing our systems.
Risk Assessments - Periodic reviews of applicable threats and vulnerabilities. We start by prioritizing risks. We mitigate, transfer or accept risks to a reasonable level. We emphasize monitoring and response activities for critical resources.
Host Security - Most hosts use the Security Content Automation Protocol (SCAP). This provides consistency and effectiveness to hardening security. There are some exceptions to this provision. Exceptions include specialty devices (e.g. incident handling laptops) and test equipment.
Network Security - We configure the network perimeter to deny activity not permitted. We secure all connection points. This includes virtual private networks and dedicated connections to other organizations.
Malware Prevention - We deploy software that detects and stops malware. We scan outside media and email file attachments before opening them. We prohibit certain types of files (e.g. .exe) via email. We restrict applications to those that have an approved business use. We restrict the use of removable media. We restrict personal device access to organizational networks.
User Awareness and Training - We make users aware of appropriate use policies of systems. We train IT staff to maintain systems to the organization’s security standards.
Protect Workflow Diagram

Detection and Analysis
It isn’t practical to develop step-by-step instructions for handling every incident. NIST recommends organizations focus on handling incidents using common attack vectors. Our plan places emphasis on the following common methods of attack:
External/Removable Media - for example, infected USB flash drives.
Attrition - brute force methods that compromise, degrade or destroy systems. For example, a Distributed Denial of Service (DDoS) attack.
Web - an attack executed from a website or web-based application. For example, a redirect that exploits a browser vulnerability and installs malware.
Email - an email message or attachment. For example, a link to malicious website in the body of an email message)
Impersonation - the replacement of something benign with something malicious. For example, rogue wireless access points.
Improper Usage - any incident resulting from a violation of the acceptable use policy. For example, a user installs file sharing software leading to the loss of sensitive data.
Theft or Loss of Equipment - the loss or theft of a computing device or media
Signs of an Incident
Signs of an incident fall into two categories. A precursor is a sign that an incident may occur in the future. An indicator is a sign that an incident may have occurred or is occurring.
Examples of precursors include announcements of new exploits or threats from a group. Examples of indicators include antivirus detecting unusual deviations from typical network traffic flows.
Our plan identifies the methods employed to detect incidents:
Network-based and host-based Intrusion Detection and Prevention Systems (IDPSs)
Security Information and Event Management (SIEM) log analyzers
Antivirus and antispam software
File integrity checking software
Third party monitoring services
Network flows
Public information
People within the organization
People outside the organization
Incident Analysis
The analysis begins when the team believes that an incident has occurred. The team determines the scope and documents who originated the incident. They also assess how the incident is occurring. This initial analysis provides enough information for prioritization. Out plan identifies practices that support initial analysis and validation of incidents:
Profile of Networks and Systems - measured characteristics of expected activity. This helps identify changes to the environment. For example, we track average network bandwidth usage at various times of day.
Defining Normal Behaviors - we study systems to baseline normal behavior. This helps us recognize abnormal behavior. For example, we review condensed log entries and investigate security alerts.
Log Retention Policy - we maintain log data from applications for a period of time.
Correlating Event Logs - we correlate events among indicator sources to verify incidents.
Synchronized Hosts - the Network Time Protocol (NTP) provides consistency in log timestamps.
Knowledge Base - the incident response team maintains a collection of helpful information. This includes text documents, spreadsheets, and databases. They contain a variety of information for quick reference during incident analysis. This includes explanations of the significance and validity of precursors and indicators.
Internet Search Engines - we investigate usual activity using internet search engines.
Packet Sniffers - we use a packet sniffer to capture network traffic. We configured it to record traffic that matches a specified criteria.
Data Filtering - we filter out categories of indicators that tend to be insignificant.
Escalation - we may consult with internal and external resources. Especially if we lack information to contain or eradicate an incident.
Incident Documentation
We document and timestamp every step taken during incident handling. The incident handler signs and dates every document related to the incident. Handlers work in teams of at least two. One person records and logs events while the other performs the technical tasks.
We restrict access to incident data as it contains sensitive information. Only authorized personnel have access to the incident database. We encrypt communications and documents so that only authorized personnel can read them.
We collect evidence according to specific procedures. This ensures we meet all applicable laws and regulations. Evidence gathering follows the four-phase forensic process. This process includes collection, examination, analysis and reporting.

Forensic tools and techniques examine data to extract relevant information. We analyze the data to answer the questions that were the impetus for performing the collection. We report results to detail other actions and improvement recommendations.
We account for evidence at all times. We use a chain of custody form when transferring evidence from person to person. This details the transfer and includes each party’s signature. We keep a detailed log for all evidence that tracks the following information:
Identifying information (e.g. serial number, model, hostname, MAC and IP addresses)
Name, title, and phone number of each individual who collected or handled the evidence
Time and date (including time zone) of each occurrence of evidence handling
Storage location of the evidence
Identifying The Attacking Hosts
Identifying an attacking host is time-consuming. It can prevent us from achieving our primary goal, minimizing business impact. We often perform the following activities to identify the attacking host.
Validating the Attacking Host’s IP Address - spoofed IP addresses limit effectiveness.
Researching the Attacking Host through Search Engines
Using Incident Databases - consolidated databases containing incident data from various organizations.
Monitoring Possible Attacker Communication Channels - monitoring internet relay chat (IRC) channels.
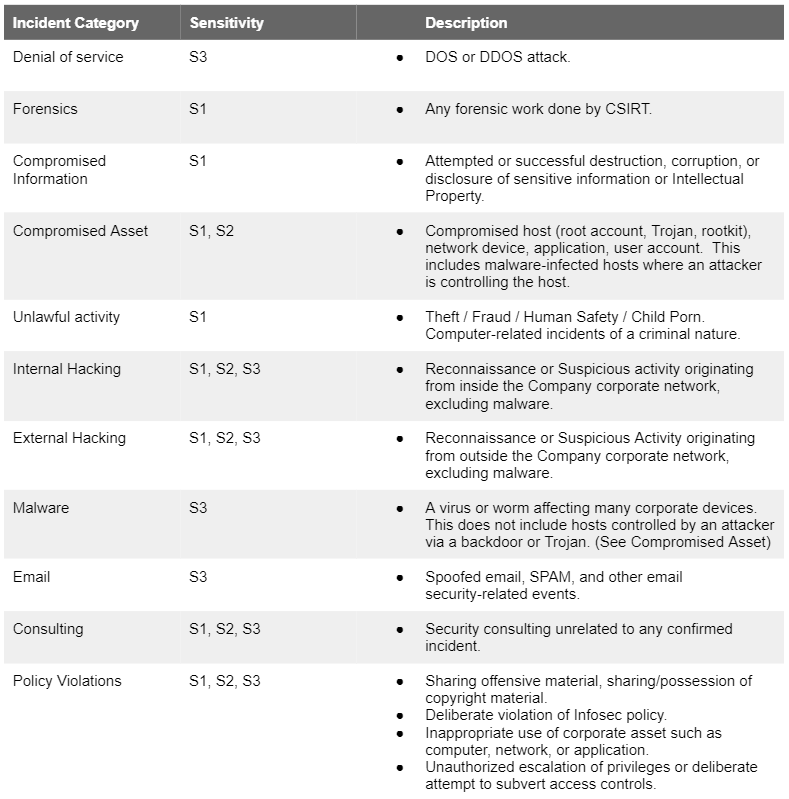
Incident Categorization
The Forum of Incident Response and Security Teams (FIRST) manages a list of categories. There are a couple reasons organizations should classify incidents. First, certain categories may warrant higher sensitivities and more restricted communications. Second, having discrete categories allows for more detailed analysis of performance. Here are the categories we identify in our policy:
Incident Prioritization
The functional and information impacts as well as the recoverability effort determine prioritization. The following tables detail the categories of each factor:
Functional Impact of the Incident - categorizes the negative impact to business functions.

Information Impact of the Incident - categorizes the effect on the organization's data. The information impact categories are not exclusive (except for "none").

Recoverability Effort of the Incident - categorizes the resources required to recover.

We calculate Business Impact by combining the functional and information impacts. We determine criticality as a function of the business impact and recoverability effort. We assign criticality levels using the CSIRT criticality matrix:

Sensitivity Levels
The FIRST incident categories relate to a sensitivity classification table. Here is how we introduced the sensitivity matrix in our plan:
Incident managers apply the “need to know” when communicating case details. The sensitivity matrix classifies cases according to sensitivity levels.
Communication methods during incident handling include the following:

Email
Website (internal, external, or portal)
Telephone calls
In person (e.g. daily briefings)
Voice mailbox greeting (e.g. the help desk-s voice mail greeting)
Paper (e.g. bulletin boards and notices on doors)
Detect Workflow Diagram

Triage Workflow Diagram

Respond
Responding to and recovering from a declared incident often requires two primary actions:
Immediate limitation or containment of the scope and impact of the incident
An appropriate response to stop the ongoing or future effect of the incident. This includes repairing any damage and restoring services.
Containment
Containment strategies vary based on the type of incident and assessed impact. Criteria for determining the appropriate strategy includes:
Potential impact
Need for evidence preservation
Service availability
Time and resources needed to put in place the strategy
Effectiveness of the strategy (e.g. partial containment, full containment)
Duration of the solution
The actual methods of containment vary depending on the systems and information affected. Containment activities for each major incident type include:

Eradication
After containing an incident, eradication will prevent the attacker from regaining access. Eradication involves eliminating components of the incident and mitigating exploited vulnerabilities. Eradication can include:
Deleting malware
Disabling breached user accounts
Installing appropriate patches
Making configuration changes
Changing passwords
Providing training to users
We conduct eradication and recovery in a phased approach. Prioritization determines remediation steps. The early phases increase the security with relative quick high value changes. The later phases should focus on longer-term changes such as infrastructure changes. Eradication actions are often Operation System (OS) or application-specific. Detailed procedures are outside the scope of this document.
Recovery
We restore systems to normal operations in the recovery phase. Recovery actions are often OS or application-specific. Detailed procedures are outside the scope of this document. Recovery may involve actions such as:
Restoring systems from clean backups
Rebuilding systems from scratch
Replacing compromised files with clear versions
Installing patches
Changing passwords
Tightening network perimeter security (e.g. firewall rulesets, boundary router access control lists)
Higher levels of system logging or network monitoring
Response Workflow Diagram

Respond to Technical Issues

Respond to Management Issues Workflow Diagram

Respond to Legal Issues Workflow Diagram

Post Incident Activities
Lessons Learned
We hold a "lessons learned” meeting within several days of a major incident. This meeting helps improve security measures and the incident handling process. We sometimes hold meetings for small incidents. Especially if they use new methods that are of widespread concern and interest. Attendees include those involved in the incident and those who might help in the future. We document notes from these meetings using the Post-incident Meeting Minutes.
Incident Reporting
We create a follow-up report for each major incident. The report includes:
Incident Details
Formal chronology of events
Post-incident Meeting Minutes
Evidence Chain of Custody forms
We conduct a post-mortem analysis immediately following a major incident. This may lead to updates made to our incident response policies and procedures. We collect actionable data throughout the incident handling process. We may use the data to:
justify more funding of incident response capabilities
identify systemic weaknesses and threats
select more controls through the risk assessment process
Evidence Retention
We keep security incident records according to the General Records Schedule (GRS). We keep computer security incident handling evidence and reports for three years. Records include:
Reporting forms
Reporting tools
Narrative reports
Background documentation
CSIRT Roles and Responsibilities

Applicable Training Requirements

Communication Guidelines
The legal department has approved information sharing with these external organizations:

Several internal departments coordinate through the incident response process, including:





